【React】ReactHookとTypeを使った型定義
こんばんは、葛の葉です。
個人で最近Reactを触れています。
ReactHookを使ったステートの変更を行うときにtypeを使うとよいということがわかりましたので連携しようと思います。
コードはこんな感じ
type SetFileTextAction = { type: "setFileText", fileText: string; }; type SetFileEncodeType = { type: "setFileEncodeType", fileEncodeType: string; } export type Action = SetFileTextAction | SetFileEncodeType; export interface MemoState { fileText: string; fileEncodeType: string; }; const reducer = (state: MemoState, action: Action): MemoState => { const c = Object.assign({}, state); switch (action.type) { case "setFileText": c.fileText = action.fileText; return c; default: return state; } };
ActionというtypeがSetFileTextActiontypeまたはSetFileEncodeTypetypeとなっているのがポイントです。
上記のコードではReducerを使った際にfileEncodeTypeのステートを変更することが出来ないので、以下のように変更するとします。
const reducer = (state: MemoState, action: Action): MemoState => {
const c = Object.assign({}, state);
switch (action.type) {
case "setFileText":
c.fileText = action.fileText;
return c;
+ case "setFileEncodeType":
+ c.fileEncodeType = action.fileEncodeType;
+ return c;
default:
return state;
}
};
その際にVSCodeはこのように表示されます。
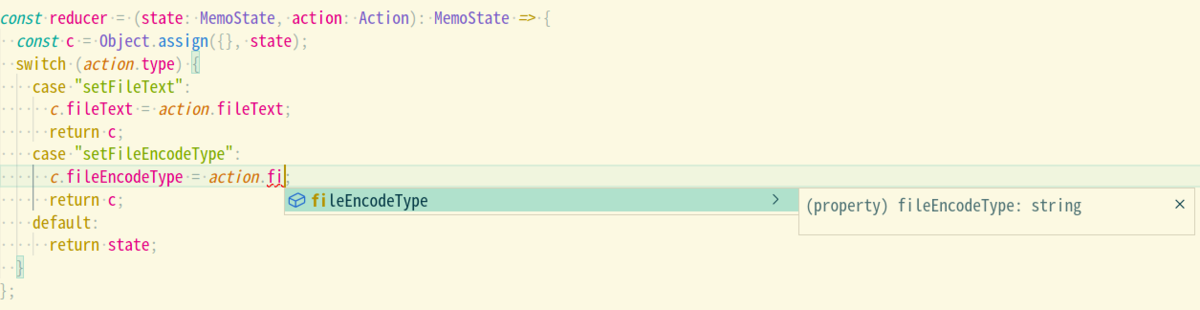
typeプロパティが"setFileEncodeType" となる型がSetFileEncodeTypeしかないため、型の特定が可能となります。VSCodeは頭良いみたいで、特定された型のactionプロパティが特定されているようです。これ使うと事故少なくて良さそう。
ついでに
簡素なメモ帳アプリ作ってます。ElectronとReactを主に使っています。
【JavaScript】typeof nullするとobjectって返ってくるぜ👀
JavaScriptでびっくりした仕様
console.log(typeof null) // "object" console.log(typeof undefined) // "undefined"
undefinedはundefinedで返ってくる。面白い。

判定させたいなら〇〇 === nullを使う感じ。。。なんだろうか👀
【雑記】不定期更新に変更します。
こんばんは、葛の葉です。
さて、5/31をもって職業プログラマーとして満二年をとげ、6月からプログラマー三年生になりました。当時、駆け出しプログラマーだった私も、少しはプロっぽくなったのかなぁと思います。プログラマーという夢をかなえることができてとても良かった。
前回にもちょっと書いたのですが、このブログの更新を不定期にしようと思います。
多分、多くの人は知らないと思うのですが、私はこのブログを週1で書いてて、それを2年間続けていました。ちょうど2年前の6月の最初の週から定期的に更新しています。
当時、樺沢紫苑さんのアウトプット大全という本がベストセラーになると、右に左にアウトプットという言葉が流行り、このブログもその位置付けで始めることになりました。
ブログを書くこと自体は結構楽しくて1年くらいは書いてて楽しかったです。ただ、途中からマンネリとなりました。
プログラマーのアウトプットはブログに書くこと以外にもある気がします。実際にアプリケーションを作るのもアウトプットです。作りきるということができれば、それは大きなアウトプットになると思います。
なので、今後は自分の作ってみたいものを作りつつ、それができたらアーキテクチャの話なども含めてブログに書こうかなぁ思います。
【Typescript】ネストなObjectが持つ文字列の全ての長さを整える
こんばんは葛の葉です。
ネストになっているオブジェクトを処理しようとすることが多くて、そのネストの深さがものによってまちまちな場合の処理書くの辛いなぁっている昨今なんですよ。色々と考えたら、これは再起処理でコードを書くのがいいんじゃないかなぁと思って今回書いてみました。
再起処理でobjectかそうでないかを判断する。
reflexiveFuncToObjectという関数を作成しました。これは第一引数に対象となるオブジェクトを入れ、第二引数にそのオブジェクトに実行させたい関数を入れます。第三引数以降はその関数に与える引数になります。この関数を実行するとオブジェクトのそれぞれのプロパティのデータ型がObjectかそうでないかを判定し、Objectの場合は再びreflexiveFuncToObject関数を実行し、そうでない場合は第二引数の関数を実行します。
interface anyObj { [key: string]: any; } const reflexiveFuncToObject = (obj: anyObj, func: Function, ...args: any) => { const copy:anyObj = {...{}, ...obj}; Object.keys(copy).forEach((key: string) => { if (typeof copy[key] === "object") { reflexiveFuncToObject(copy[key], func, ...args); } else { copy[key] = func(copy[key], ...args); } }); return copy; };
以下のような値を変更するような関数を作ります。reflexiveFuncToObject関数の第一引数に入れてあげるようにします。
const truncate = (prop:any, l: number) => { if (typeof prop !== "string") return prop; return l >= prop.length ? prop : (prop.substr(0, l) + "..."); }; const add = (prop: any, num: number) => { if (typeof prop !== "number") return prop; return prop + num; };
以下の状況においてはこのようになります。
const object1 = { a: "aaaaa", b: "bbbbb", c: 1, }; console.log(reflexiveFuncToObject(object1, truncate, 1)); // { a: 'a...', b: 'b...', c: 1 } console.log(reflexiveFuncToObject(object1, add, 1)); // { a: 'aaaaa', b: 'bbbbb', c: 2 }
再起処理って初めて書いたかも
2年この仕事してるんだけど再起処理は初めて書いたかもしれない。今回再起処理を書いてみようと思ったのはチャレンジ心だけなんだ。もっといい処理の仕方は絶対あると思うけど、ネストなオブジェクトに対して再起処理はいいアプローチだと思っている。今後もチャレンジしてみたい。
最初はしょぼくたっていいんだ。後からかっこよくすりゃいいんだ。
追伸
次回以降は不定期に気まぐれに更新します。
【TypeScript】Objectのディープコピー
こんばんは葛の葉です。
Javascriptのディープコピーをちょっと書きます。Javascriptではconst copyedObj = JSON.parse(JSON.stringify(obj));を使うと思います。
const obj1 = { hoge: 1, piyo: "hiyoko", fuga: true }; const copyedObj1 = JSON.parse(JSON.stringify(obj1)); obj1.hoge = 2; console.log(copyedObj1.hoge === 1); // true console.log(copyedObj1); // { hoge: 1, piyo: 'hiyoko', fuga: true }
しかし、以下のStackOverflowには
Fast cloning with data loss - JSON.parse/stringify If you do not use Dates, functions, undefined, Infinity, RegExps, Maps, Sets, Blobs, FileLists, ImageDatas, sparse Arrays, Typed Arrays or other complex types within your object, a very simple one liner to deep clone an object is: JSON.parse(JSON.stringify(object))
Date型や関数, undefined, Infinityや正規表現、その他もろもろのものについてはコピーできないということです。
const obj2 = { moge: undefined, date: new Date("2020/01/01Z"), func: function () { return 'hogehoge'; }, reg: /^https/g }; const copyedObj2 = JSON.parse(JSON.stringify(obj2)); console.log(copyedObj2); // { date: '2020-01-01T00:00:00.000Z', reg: {} };
Date型はJSONになるタイミングでISO 8601形式のstring型になります。正規表現オブジェクトについては、空のオブジェクトに変更されます。こういった一部の型についてはコピーすることが出来ないようです。おそらくJsonが文字列しかないからなのかなぁって思います。
じゃあどうやってディープコピーするの?
先のStackOverflowにも書いてあったんですけど、頑張ってコード書いてもいいけど基本的にライブラリやフレームワークのメソッドを使おうってことみたいです。私が使ったのはこちらのライブラリ。
Typescriptの型はこちら
import clone from "clone"; const obj2 = { moge: undefined, date: new Date("2020/01/01Z"), func: function () { return 'hogehoge'; }, reg: /^https/g }; const copyedObj2 = clone(obj2); console.log(copyedObj2); /* { moge: undefined, date: 2020-01-01T00:00:00.000Z, func: [Function: func], reg: /^https/g } */ console.log(copyedObj2.func()); // hogehoge
【Python】janomeで形態素解析をしてもらう
こんばんは葛の葉です。
Pythonにはjanomeという形態素解析が出来るモジュールがあるみたいです。
親譲《おやゆず》りの無鉄砲《むてっぽう》で小供の時から損ばかりしている。小学校に居る時分学校の二階から飛び降りて一週間ほど腰《こし》を抜《ぬ》かした事がある。なぜそんな無闇《むやみ》をしたと聞く人があるかも知れぬ。別段深い理由でもない。新築の二階から首を出していたら、同級生の一人が冗談《じょうだん》に、いくら威張《いば》っても、そこから飛び降りる事は出来まい。弱虫やーい。と囃《はや》したからである。小使《こづかい》に負ぶさって帰って来た時、おやじが大きな眼《め》をして二階ぐらいから飛び降りて腰を抜かす奴《やつ》があるかと云《い》ったから、この次は抜かさずに飛んで見せますと答えた。
これをboc.txtとして保存し、pythonではこれをロードして使ってみます。
from janome.tokenizer import Tokenizer import re t = Tokenizer() moji = "" with open("./boc.txt", mode="r", encoding="utf-8") as text: moji = text.read() moji = re.sub("《[^》]+》", "", moji) moji_list = moji.split("。") moji_list.pop() s = [t.tokenize(sentence) for sentence in moji_list] # 全文の形態素解析の表示は辛いので一文だけという意味で[0] for i in s[0]: print(i) """ 親譲り 名詞,一般,*,*,*,*,親譲り,オヤユズリ,オヤユズリ の 助詞,連体化,*,*,*,*,の,ノ,ノ 無鉄砲 名詞,一般,*,*,*,*,無鉄砲,ムテッポウ,ムテッポー で 助詞,格助詞,一般,*,*,*,で,デ,デ 小 接頭詞,名詞接続,*,*,*,*,小,ショウ,ショー 供 名詞,サ変接続,*,*,*,*,供,キョウ,キョー の 助詞,連体化,*,*,*,*,の,ノ,ノ 時 名詞,非自立,副詞可能,*,*,*,時,トキ,トキ から 助詞,格助詞,一般,*,*,*,から,カラ,カラ 損 名詞,一般,*,*,*,*,損,ソン,ソン ばかり 助詞,副助詞,*,*,*,*,ばかり,バカリ,バカリ し 動詞,自立,*,*,サ変・スル,連用形,する,シ,シ て 助詞,接続助詞,*,*,*,*,て,テ,テ いる 動詞,非自立,*,*,一段,基本形,いる,イル,イル """
まず、ルビが不要なので正規表現で削除します。また、一文ずつのほうが解析として見やすいので一文にします。
tokenizeメソッドを使うことで文字列を形態素解析し、形態素を要素としてリストとして出力します。本当にこれ無料で使っていいのか?って思う。
わかち書きもしてもらう
janomeにはわかち書きにしてくれるモードもついているので、それも使ってみます。
from janome.tokenizer import Tokenizer import re t = Tokenizer() moji = "" with open("./boc.txt", mode="r", encoding="utf-8") as text: moji = text.read() moji = re.sub("《[^》]+》", "", moji) moji_list = moji.split("。") moji_list.pop() s = [t.tokenize(sentence, wakati=True) for sentence in moji_list] # 全文の形態素解析の表示は辛いので一文だけという意味で[0] print(s[0]) """ ['親譲り', 'の', '無鉄砲', 'で', '小', '供', 'の', '時', 'から', '損', 'ばかり', 'し', 'て', 'いる'] """
【python】collections.Counterオブジェクトで文字数を保持する
こんばんは葛の葉です。
個人的な話ですが、Pythonを久しぶりに使うことになりそうなので勉強中です。
久しぶりに触ったらcollections.Counterオブジェクトというものが出てきたので触ってみることにしました。
collections.Counter
collections.Counterは辞書型のサブクラスで、Keyに要素を入れ、valueがそのカウントを保存して使うものらしいです。
公式ドキュメントはこちら↓。
かの有名な復活の呪文の数をCounterオブジェクトへ
ドラクエ2に出てくる「もょもと」の復活の呪文に出現する「ぺ」の数をカウントして保存してみます。
ゆうていみやおうきむこうほりいゆうじとりやまあきらぺぺぺぺぺぺぺぺぺぺぺぺぺぺぺぺぺぺぺぺぺぺぺぺぺぺぺ
import collections password = "ゆうていみやおうきむこうほりいゆうじとりやまあきらぺぺぺぺぺぺぺぺぺぺぺぺぺぺぺぺぺぺぺぺぺぺぺぺぺぺぺ" counter = collections.Counter() parsed_password = list(password) for i in parsed_password: counter[i] += 1 print(counter) # Counter({'ぺ': 27, 'う': 4, 'ゆ': 2, 'い': 2, 'や': 2, 'き': 2, 'り': 2, 'て': 1, 'み': 1, 'お': 1, 'む': 1, 'こ': 1, 'ほ': 1, 'じ': 1, 'と': 1, 'ま': 1, 'あ': 1, 'ら': 1})
ぺの数は27個らしい!
ついでにピクル化もしてみよう
Pythonではpickleモジュールを使ったシリアライズとデシリアライズもよくやってるようですのでこちらも使ってみます。
pickleの公式ドキュメントはこちら
import collections import pickle password = "ゆうていみやおうきむこうほりいゆうじとりやまあきらぺぺぺぺぺぺぺぺぺぺぺぺぺぺぺぺぺぺぺぺぺぺぺぺぺぺぺ" counter = collections.Counter() parsed_password = list(password) for i in parsed_password: counter[i] += 1 print(counter)# Counter({'ぺ': 27, 'う': 4, 'ゆ': 2, 'い': 2, 'や': 2, 'き': 2, 'り': 2, 'て': 1, 'み': 1, 'お': 1, 'む': 1, 'こ': 1, 'ほ': 1, 'じ': 1, 'と': 1, 'ま': 1, 'あ': 1, 'ら': 1}) with open("count_password.pkl", "wb") as f: pickle.dump(counter, f)
こうすることでカレントディレクトリにcount_password.pklというバイナリファイルが作成されます。このバイナリファイルはpythonでロードすることが出来ます。公式ドキュメントにも記載はありましたが、セキュアには出来ないから安全と確信できないピクルは使わないようにとのこと。
import pickle with open("count_password.pkl", "rb") as f: counter = pickle.load(f) print(counter) # Counter({'ぺ': 27, 'う': 4, 'ゆ': 2, 'い': 2, 'や': 2, 'き': 2, 'り': 2, 'て': 1, 'み': 1, 'お': 1, 'む': 1, 'こ': 1, 'ほ': 1, 'じ': 1, 'と': 1, 'ま': 1, 'あ': 1, 'ら': 1})
先と同じものが標準出力に表示されました。